如果你用过 AI 生图,你应该经历过一种很微妙的崩溃。
你满怀期待地输入:“帮我做一张活动海报,标题写夏日大促全场五折。”几秒钟后,AI 给你吐出来一张图。构图完美,光影绝佳,配色高级得像某个4A公司花了二十万做出来的。
但你把图放大一看,上面的字是这样的:“夏月大足,全土五析。”
不是拼错了,就是缺胳膊少腿。要么干脆就是一串你认不出来的乱码。
笑死,这不是你运气不好。这是整个 AI 生图行业持续了三年多的集体尴尬:画啥像啥,写字就废。不管你用的是 Midjourney 还是 Stable Diffusion ,面对带文字的图,结果都差不多。
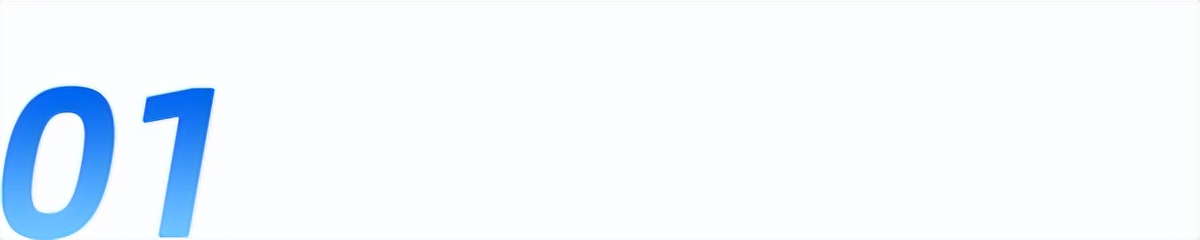
直到昨天,一家叫 Ideogram 的加拿大公司,扔出了一个 9.3B 参数的开源模型 Ideogram 4.0 。在文字渲染这个“行业绝症”上,它干了件让所有人大跌眼镜的事。

*官网截图
画了三年,连个 STOP 都拼不对
你可能会问,文字不就是一些笔画吗?画人脸比写字难多了吧?AI 人脸都能给你画得毛孔分明,为啥四个字母就搞不定?
这事还真不一样。
主流的 AI 生图模型,Stable Diffusion、Midjourney、DALL-E,它们的“大脑”分成两部分:一个负责理解文字,也就是文本编码器;一个负责画图,也就是图像生成器。中间靠“交叉注意力”来沟通。
翻译成人话就是:你写一段话,编码器把它翻译成“内部黑话”,然后传话给画画的那个部分。坏就坏在传话环节,信息是有损耗的。
打个比方。你让一个人看一张写着“ STOP ”的路牌照片,然后让他口头描述给另一个人去画。结果画出来的“ STOP ”可能变成“ SOTP ”。这就是传话损耗。
CLIP 和 T5 这些传统文本编码器,本质上是“看图说话”练出来的。它们擅长理解“这张图里有什么”,但不擅长理解“这个字长什么样”。一个字对它们来说,跟一片树叶的纹理没啥区别。都是图案。
所以 Midjourney 花了三年、七个大版本迭代,文字准确率依然只有 40% 左右。不是它不想做好,底层架构决定了这事它天然就不擅长。
但你猜 Ideogram 怎么做的?它说,我不传话了,我让文字和图像一起画。
*自制图
93 亿参数小个子,怎么打赢 800 亿巨无霸
先看一个反直觉的数据。
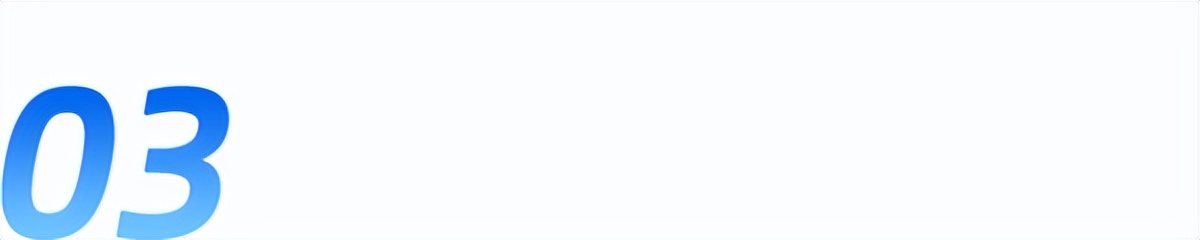
Ideogram 4.0 只有 93 亿参数。作为对比,FLUX.2 有 320 亿,腾讯的混元 Image 3.0 是 800 亿的参数的大模型。但文字渲染表现上,Ideogram 全面超越这两家。
怎么做到的?翻了它 GitHub 上的技术文档,发现核心是三个字:不走老路。
第一个不走老路,叫“ 单流 DiT 架构 ”。
传统做法是双流:文字一条管道,图像一条管道,中间靠交叉注意力传话。而 Ideogram 的单流架构,是把文字 token 和图像 token 拼接成一个统一序列,扔进同一个 34 层 Transformer 里。
什么意思呢?在它的“大脑”里,文字不是被翻译后传进去的外部信息。文字和像素、颜色、构图一起,作为画面的“原生组成部分”被思考。
这就像让一个人同时写字和画画。不是让一个人写了字交给另一个人去描。
第二个不走老路,是文本编码器。它没用 CLIP ,没用 T5 ,而是用了 Qwen3-VL ,一个真正的视觉语言模型。这哥们儿是能“ 看懂图 ”的,不是只会“看图说话”的。而且它不是只从一个层提取特征,是从 13 个中间层同时抽,相当于从“粗看”到“细品”一次性全拿了。
第三个不走老路,更狠。
Ideogram 的训练数据,不是在“图片加描述”上训练的,而是在结构化 JSON 标注上训练的。每张训练图都有详细标注:标题在哪个位置、正文是什么字体、背景是什么颜色。
这意味着,模型学到的不只是“画一张有字的图”,而是“理解排版逻辑”。
效果怎么样?ContraLabs 搞了个文字渲染盲测排行,让真正的设计师来打分。
注意,这是专门针对排版质量的测试,参与者是真实设计师。不是爱好者投票,不是社区打分,是专业用户用脚投出来的。
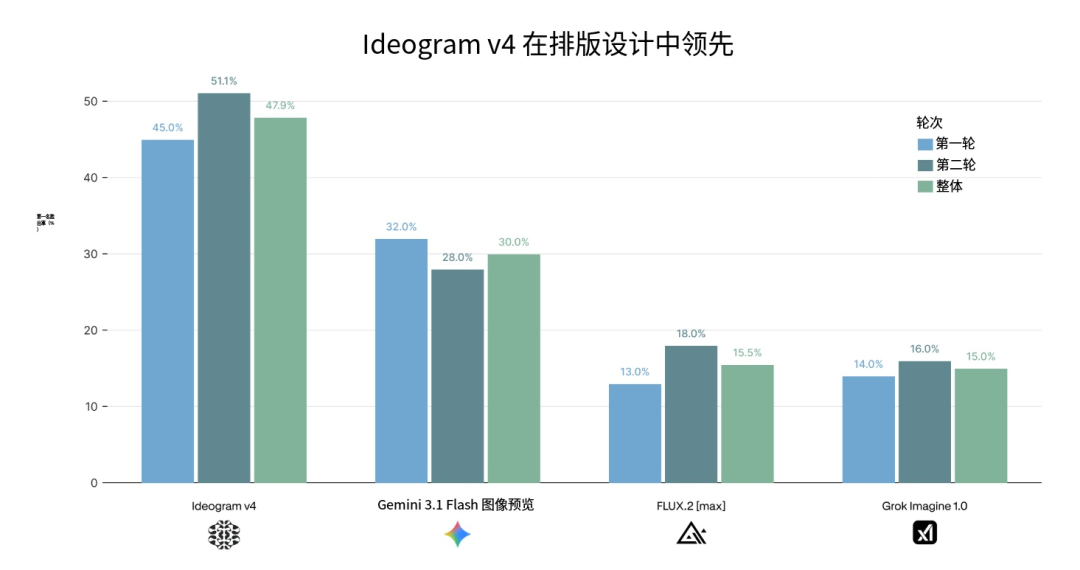
*ContraLabs 文字渲染盲测排行截图
而且它不只有文字强。
原生 2K 分辨率、支持 6:1 超宽画幅、色板调色控制、JSON 结构化提示,这些功能放在一起,结果就是:
你不光能用它做海报和 LOGO,还能做横版封面、竖版手机壁纸,配色都能精确指定。
该说不说,这已经不是“画图”的级别了,是“交付设计稿”。
开源这把刀,砍在了谁身上
到这里你可能觉得:技术很强,跟我有啥关系?
关键来了。Ideogram 4.0 是开源的。更准确地说,是“开放权重”。你可以在自己的机器上跑它、用自己的数据微调它、在自己的产品里集成它。
当然,有个但。商业使用要付费。
听起来有点像“打着开源的旗号搞商业”对吧?但说实话,这恰恰是 Ideogram 最聪明的一步棋。
你看,AI 生图这个赛道过去几年演化出了三种生存策略。Stable Diffusion 的“全开源赌生态”路线,结果 SD3 崩了,连创始人都跑路了。Midjourney 的“全闭源赌品质”路线,赚到了钱,但用户被锁在 Discord 里。GPT-Image 和 Imagen 的“大厂绑套餐”路线,技术强但是贵。
Ideogram 选了第四条路:权重给你白嫖,商业再说。这招最妙的地方,能在最短时间内把生态铺开。
果不其然。发布 24 小时内,HuggingFace、ComfyUI、Replicate、Leonardo AI、Krea AI、Picsart、Cloudflare,14 个以上的平台宣布接入。
好家伙,这意味着设计师不需要换工具,在自己熟悉的 ComfyUI 或 Krea 里就能用上 Ideogram 4.0 。而 Midjourney 呢?还在跟 Discord 一个聊天软件绑死。
哦对了忘了说,API 价格也相当感人。最快模式 0.03 美元一张,最高质量 0.1 美元一张。花不到一块钱人民币,就能生成一张能直接用的海报。
*开源生图模型参数效率对比
那问题来了,谁在慌?
先说 Midjourney。文字渲染一直是它的软肋,但以前大家都没解决好,所以它可以说“ AI 生图都这样”。现在 Ideogram 直接干到了碾压级,这个借口没了。尤其是在海报、LOGO 、封面、社媒素材这些商业设计场景,文字是刚需,Midjourney 在这个赛道上基本被降维打击。
但设计师没那么容易慌。工具再强,你得知道“五折”这两个字放哪儿好看、用什么字体不违和、配色怎么不翻车。这个判断,目前还是人的活儿。
真正可能被冲击的,是Canva和稿定设计这类模板工具。如果AI能精准生成带文字的设计稿,几百套模板的意义还剩多少?
不过也要说句实在话。目前 Ideogram 4.0 的中文文字渲染效果还不明确,评测主要基于英文。而且它的“开源”有限制:非商业免费,商业要买许可证。这跟 Stable Diffusion 那种可以随便商用的真开源不是一回事。
文字之后,下一个战场
Ideogram 4.0 真正值得关注的地方,不是它“又开源了一个模型”。而是它证明了:AI 生图最被低估的那块短板,其实是可以靠架构创新填上的,不一定非得堆更大的模型。
但这不是终点。
文字渲染被封堵之后,AI 生图还剩几块拼图没拼上。
第一块是角色一致性。生成一个主角的十张图,十张脸都不一样。虽然这方面一直有在进步,但这个尴尬至今没有模型能彻底完美解决,别说做漫画了,做个连续的产品展示图都得撞运气。
第二块是精细编辑。你说“把标题改成绿色”,多数模型要么不理你,要么把整张图给你重新画一遍。好消息是,Ideogram 官方已经预告“可编辑文本和图层功能即将上线”。如果真做出来,那才是真正的“ AI 版 Photoshop ”。
第三块是中文。对,咱们最关心的。目前全球顶尖的生图模型,对中文文字的支持基本等于零。这恰恰是国产模型的机会窗口。通义万象、即梦AI,听到没?
不过话说回来,文字的窗口期不会太长。Midjourney V8 已经在测试改进文字渲染,FLUX 也在追。估计 6-12 个月内,“ AI 能写字”就会从差异化变成标配。
到那个时候,拼的就不再是“谁能写字”,而是“谁能设计”。
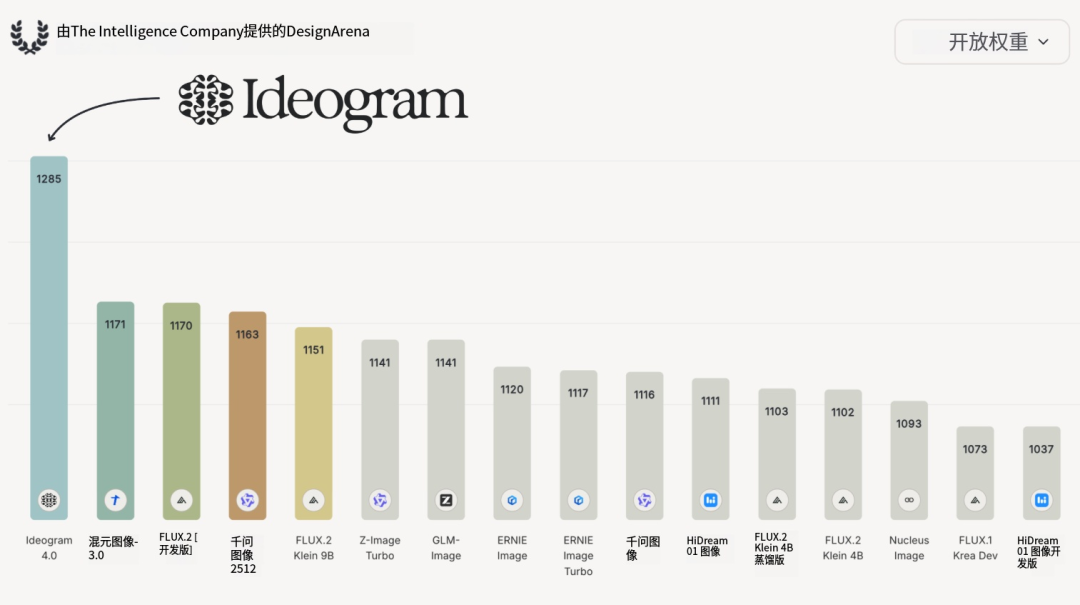
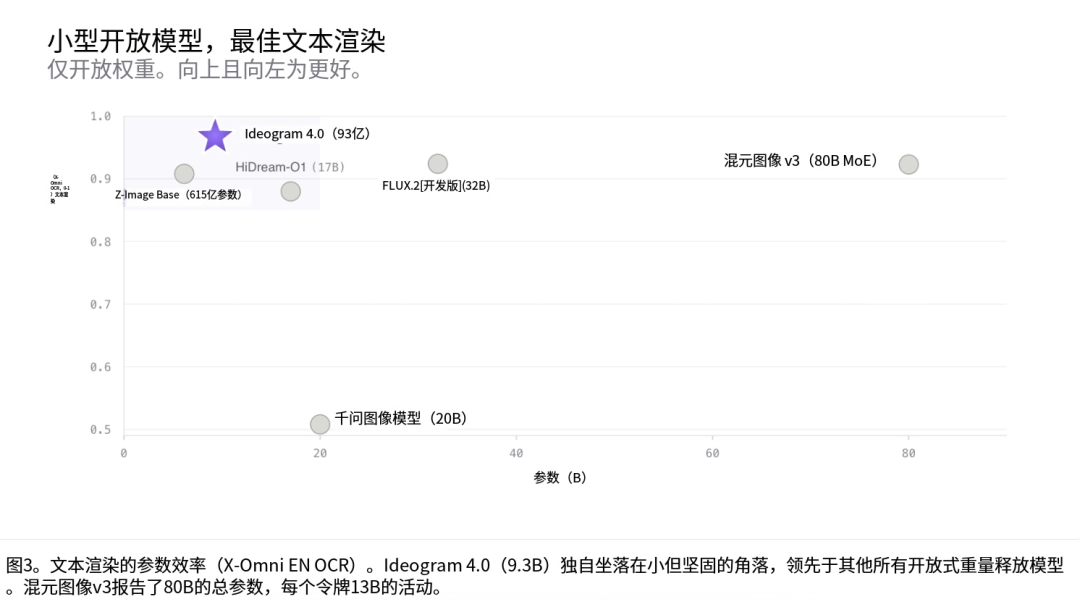
*Design Arena 开源生图模型排行榜
从“ AI 画啥像啥、写字就废”到“开源模型把 Midjourney 给秒了”,这条路走了三年多。
当年第一波 AI 生图火起来的时候,设计师们一边惊叹一边冷笑:画得再好看有什么用,你连个像样的 LOGO 都做不出来。
那个冷笑,被 Ideogram 4.0 给堵上了。说白了,不是 Ideogram 有多神,而是整个行业在这个问题上憋太久了,一个敢走新路的人冲出来,自然就成了破局者。
但真正重要的是,Ideogram 4.0 的对手不是 Midjourney 。它的对手是“ AI 到底能不能真正干活”这个终极问题。文字渲染,只是回答这个问题的第一步。
以前你让 AI 做个海报,你得先祈祷它能写对字,然后自己开 Photoshop 改。以后,这个过程可能变成:说一句话,AI 给你一张能用的成品。
问题是,到那个时候,你打算用它做什么?
数据来源与参考资料
评测数据:ContraLabs盲测、DesignArena排行榜、The Decoder
对比评测:pxz.ai (50小时实测)、uuaihub多工具横评
综合:IT之家、新浪科技、The Decoder、deogram 官方、GitHub、assets
编辑:HQL
