这几天在北京出差,正好碰上火山引擎 FORCE 原动力大会,刚好没啥事,就顺道过来看看。现场真是“人多到爆炸”,我费了好大劲才硬挤进去,贴墙站了两小时...
说真的,今年我参加过不少发布会,印象中只要是跟 AI 沾边的,无一例外全都是人挤人,上次参加一个AI相关的会,都没挤进去内场,尴尬!这也说明,现在大家对 AI 进展的都很关注。
今天的大会现场,火山引擎也确实掏出了不少好东西::Seedance 2.5 模型,豆包大模型 2.1Pro 等等...

两个小时老狐实际听下来,最大的感受就一个字:密。
不是那种PPT画饼式的密,是那种“你还在消化上一个、下一个已经端上来了”的密。
这不,刚从会场出来,趁热乎,第一时间给大伙把重点捋一遍。

一、谭待开场,先亮家底
火山引擎总裁谭待第一个上台,没废话,直接甩数据。

豆包大模型的日均Tokens调用量干到了180万亿。什么概念呢?两年前刚发布的时候,这个数连现在的零头都不到,增长超过了1500倍。光过去一年,又翻了10倍。看来用豆包大模型的人和场景,正在以肉眼可见的速度膨胀,而且没有任何要停的意思。
还有一个数据老狐印象很深:国内公有云MaaS市场,火山引擎占了49.5%。也就是说,中国企业每消耗两个大模型Token,就有一个跑在火山引擎上。
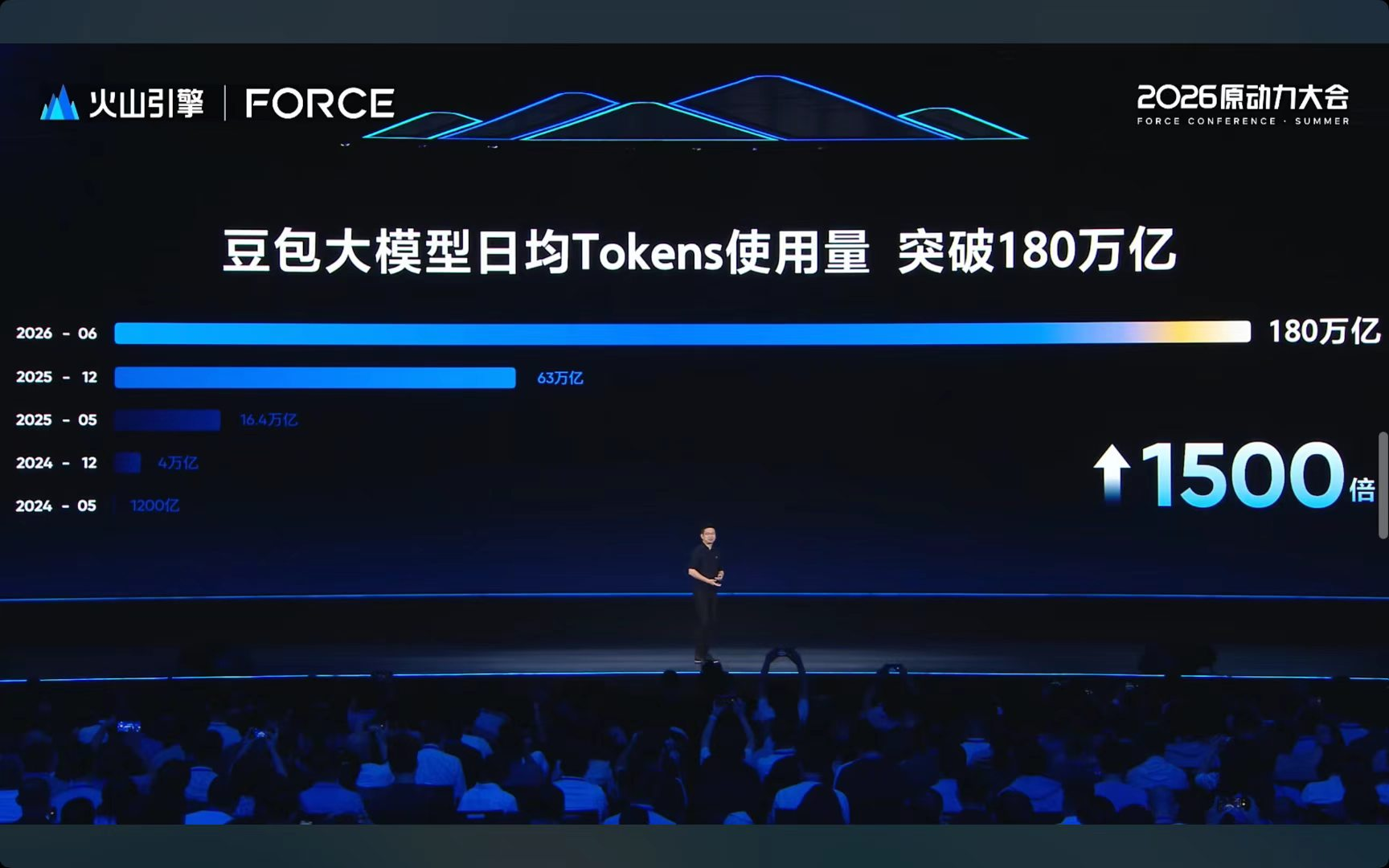
谭待还提了一嘴“万亿Tokens俱乐部”,年度累计调用超万亿的企业。去年12月只有100家,半年过去,这个数翻到了200多。这些企业基本覆盖了你能想到的主流行业:金融、教育、制造、政企。

字节跳动CEO梁汝波录了一段视频,说了句大白话:“以前企业都在问要不要做AI,现在大家问的是怎么做AI。”他把字节今年的关键词定成了“勇攀高峰”,原话是:攀登AI高峰是字节当下最重要的事。

二、豆包2.1 Pro:字节把压箱底的模型端出来了
信息量最大的部分,是新旗舰模型豆包2.1 Pro的发布。
先看Coding。谭待给了三个硬核评测成绩:Terminal Bench 2.1,业界公认最贴近真实开发终端的评测,豆包2.1 Pro跟 Anthropic 的 Opus 4.7 基本打平,略低于OpenAI的GPT5.5,进入全球第一梯队。
Scicode,科学计算代码评测,覆盖五大学科,59.8分,压过了GPT 5.5和Opus 4.7。NL2Repo-Bench,仓库级代码生成,从一份数学文档出发从零生成整个仓库,47分,明显超过GPT 5.5和Gemini 3.1。
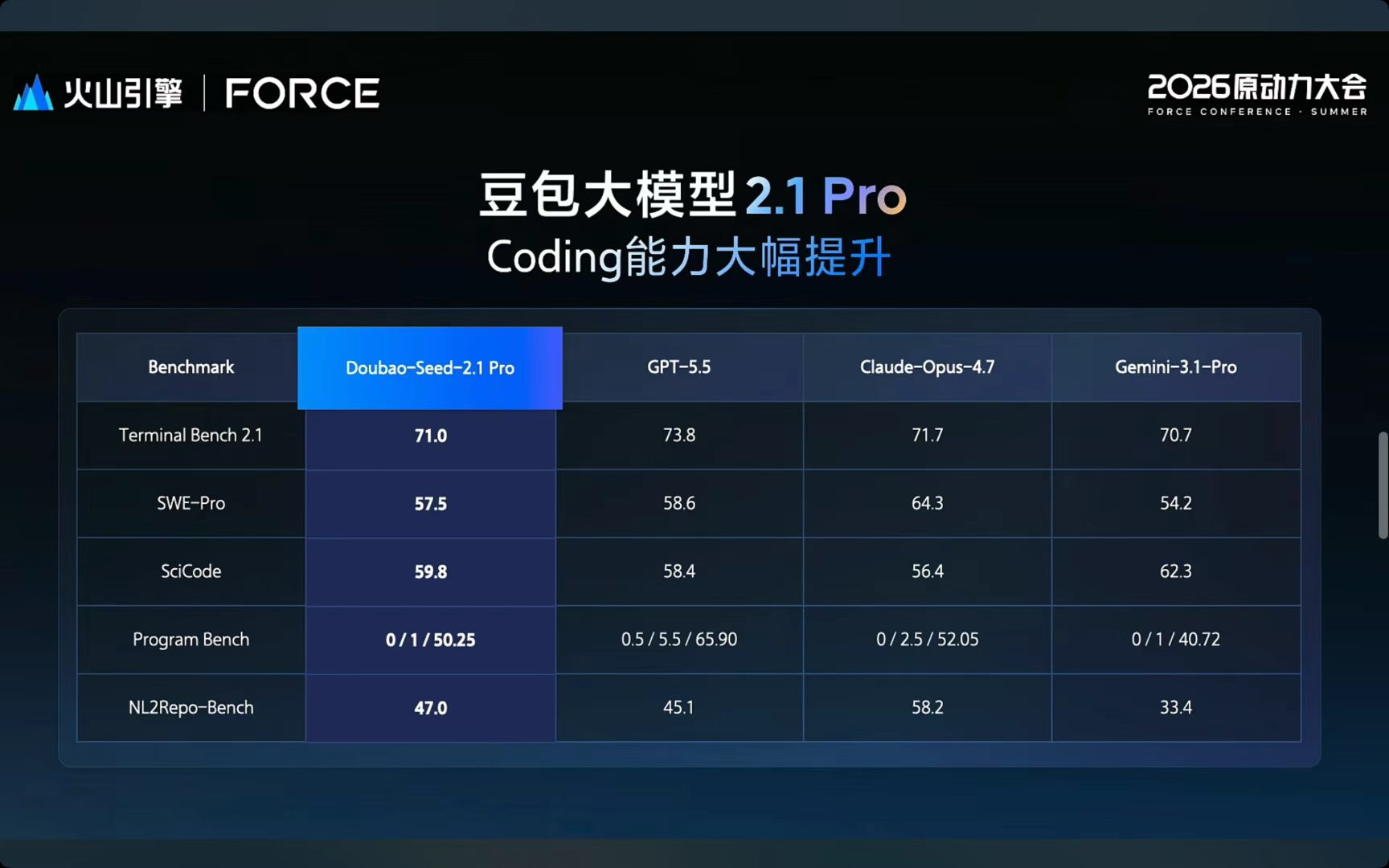
以前大模型写代码,写个小函数还行,一碰到真实工程就崩。这次豆包2.1 Pro是真的能扛工程级任务了。
谭待现场放了个demo,让模型连续跑了18个小时,完成了一个芯片RTL设计的完整流程:6个核心模块、1300多行代码,还自己跑通了仿真测试。放在以前,这事得3到5个资深工程师干好几周。

Agent能力也拉满了。GDPVal是OpenAI发布的真实世界企业任务评测,覆盖9大行业14种职业,豆包2.1 Pro国内第一。MCP-Atlas测的是AI Agent调用真实工具的能力,包含30个MCP Server、220个工具、1000多个任务,豆包2.1 Pro全面超过了Opus 4.7和GPT 5.5。
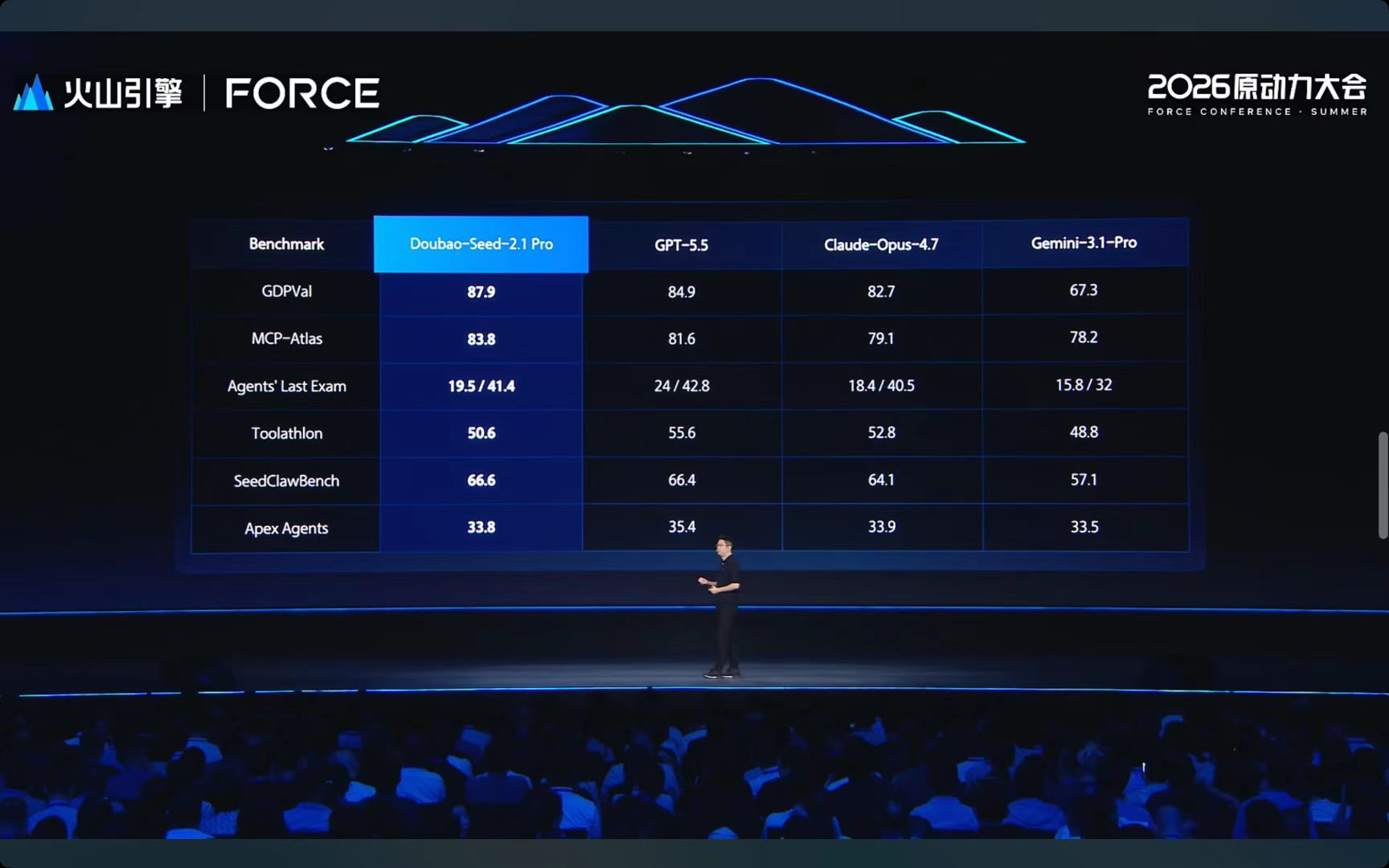
多模态理解本来就是豆包的强项。这回在视频理解的两个权威榜单Tomato和LVBench上,都把Gemini 3.1甩在了后面。GUI Agent方面,在桌面端操作能力上接近Opus 4.7,移动端多项SOTA。
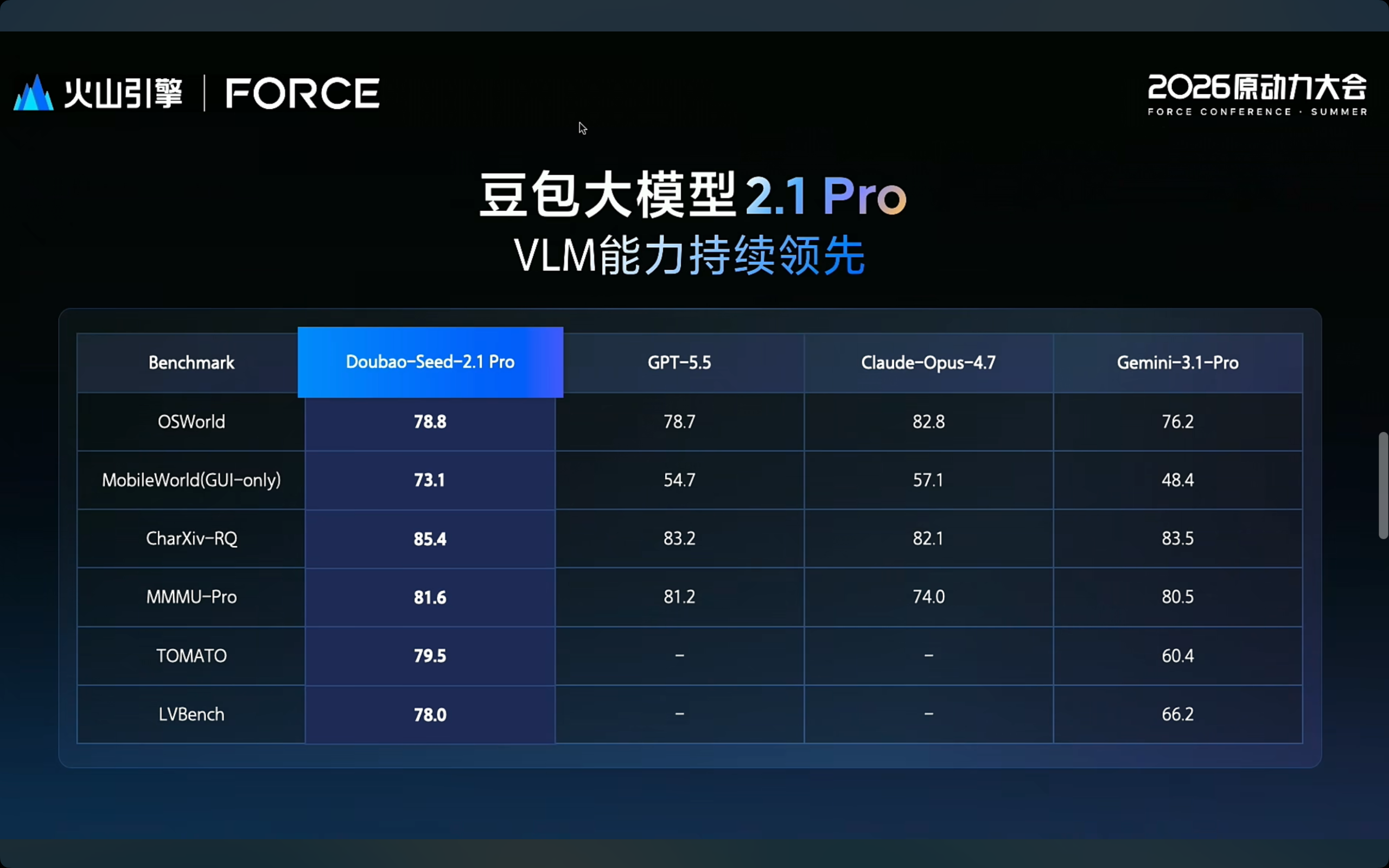
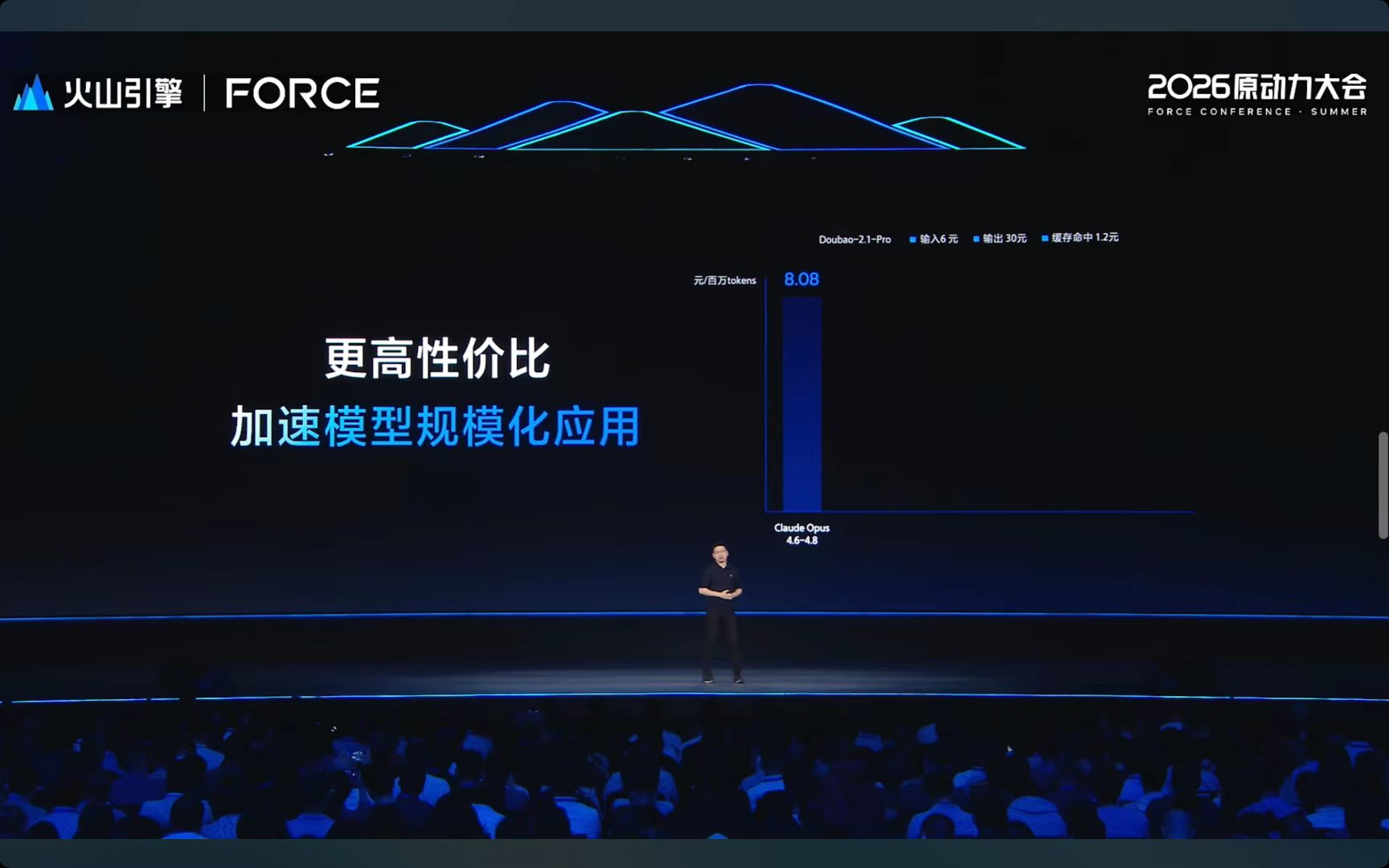
但老狐觉得最狠的不是性能,是价格。
豆包2.1 Pro百万Tokens统一定价:输入6块,输出30块,缓存命中只要1块2。谭待直接拿OpenAI做对比:综合使用成本比Opus 4.6到4.8系列低了接近80%。
简单说就是:性能追上了,价格只要对手的两折。
这还没完,谭待还端了个Turbo版本出来,能力保持在较高水平,价格再砍一半。
字节技术副总裁洪定坤也上台了,讲的是字节内部怎么用AI写代码。他给了两个数:Trae团队的AI代码贡献率已经超过90%,人均需求吞吐率提升了60%,到了原来的1.6倍。
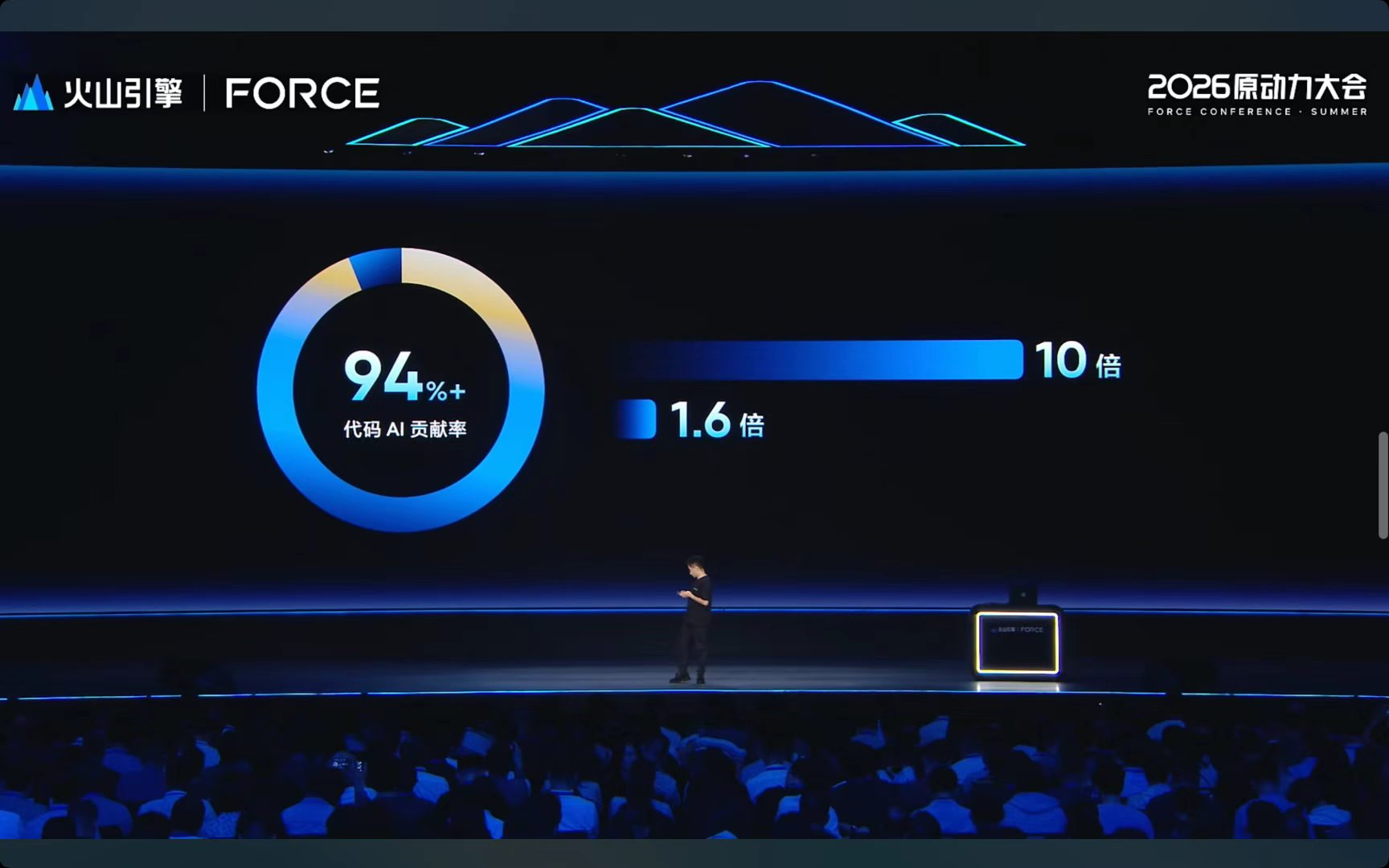
但他说了句挺实在的话:AI写代码的速度比人快10倍不止,可效率只提了1.6倍,中间差的那一大截,就是工程落地要填的坑。不是什么都能“Vibe Coding”一下就上线的。
顺便,Trae Work企业版也发布了,给非技术岗位也能用的AI办公平台。
三、视频、图像、音频:全家桶一次端齐
语言模型讲完,视频模型Seedance 2.5接上。
老狐觉得这是全场最炸的发布之一。三点:单段视频最长30秒,全球第一。支持最多50个全模态素材联合输入,也是全球最多。原生4K,加上4K 10-bit高位深直出。

以前AI做视频,10秒到头了,稍微复杂的镜头就得一段一段拼。现在30秒一镜直出,广告、科普短片这种场景基本够用了。50个素材联合输入什么概念呢?你给一段文字描述,再给角色图、场景图、参考风格,它全吃进去,给你一次性编排好。

现场演示了一个影视白模预演的例子:一个复杂度接近10万面的宇宙飞船模型,豆包2.5在镜头缓慢推进中稳稳地保持住了结构比例,同时完成了材质渲染和光影生成。这个能力对影视行业的前期预演来说,省的不是一点点时间。
编辑能力也可圈可点。广告场景里,画面其他部分不动,只换模特的口红色号,一条过。

然后是图像模型Seedream 5.0 Pro。核心升级两个:交互式精准编辑和多图层分离。
你可以直接在画面上圈选、箭头标注,告诉模型“把树上的松鼠移到左边的树桩上”“右下角加两只猫的结婚照”,它理解你的空间意图然后执行。多图层分离更好玩:圈什么拆什么,小到一行字、大到整个物体,拆完还能拖拽缩放。

还有个容易被忽略但实际很实用的能力:原生支持14种语言生成图像。阿拉伯语的从右向左排版、泰语的声调符号堆叠,模型能自动适配,不是先翻译再贴字那种假的多语言。

音频这边也憋了个大招。豆包音频生成模型1.0:一段文字描述,直接生成带多角色对白、情绪、方言口音、背景音乐、环境音效的影视级音频。
现场放了一段武侠短剧demo,劫镖、对骂、打斗,所有声音都是模型直出的,没有任何人工录音。老狐当时听着就觉得,以后有声书、播客、短剧配音这些活,门槛要被拉到地板了。
语音合成模型也升到了2.0,覆盖超过15种语言合成、超过20种语言声音复刻。

哦对了,还插了个挺有意思的事。火山引擎正式上线了AI版权商业化平台,首批合作对象是周星驰的比高集团:《喜剧之王》《食神》《长江七号》三部经典电影的IP拿到了AI创作授权。现场放了段AI短片,星爷的经典桥段用豆包模型重新演绎了一遍。

四、汽车先跑通了,700万台只是开始
听完整场发布会,老狐最大的感受其实是另外一件事:豆包的落地速度。
谭待给了一组数字:搭载豆包大模型的智能汽车已经超过700万辆,覆盖50个品牌、145款车型,搭载量行业第一。金融行业服务了超过八成系统重要性银行、超过九成头部券商。全球Top 10手机厂商里9家接了豆包。超过7亿台智能终端跑着豆包模型。

这些数字背后有个逻辑:大模型这个东西,闷头搞评测打榜是一回事,真正塞进车机、手机、银行系统里稳定跑起来,是另一回事。
除了汽车,Agent落地也在加速。火山引擎的AgentKit和HiAgent 3.0已经接入了大量企业,中金财富在会上宣布了基于HiAgent搭建的AI投顾系统。ArkClaw企业版也正式发布了,安踏、瑞幸、海底捞这些你天天用的品牌已经在用。

散场前唠两句
说实话,在去之前老狐对火山引擎的印象还停留在“字节云”这个标签上。
但两小时坐下来,看到的东西跟想象的完全不是一回事。这是一家已经把模型、开发工具、Agent平台、行业落地方案、安全合规体系全部串成一条链的公司。从底层模型到上层应用,从API调用到整车座舱,中间几乎没有断点。

梁汝波说“攀登AI高峰是字节最重要的事”,谭待说“模型已经跨越了生产质变点”,洪定坤说“AI写代码很快,但工程落地才是硬仗”。
三句话串在一起,大概就是这次FORCE大会想讲的全部故事。

大会明天还有一天,开发者专场。老狐先回去消化消化。你们看完这些发布,觉得哪个最可能先用起来?是那个价格打到两折的豆包2.1 Pro,还是30秒一镜直出的Seedance 2.5?评论区唠唠。